Creating Paperoni - Part 3 of X: A year of Paperoni
While working on the release for April 2021, I went back through my commits and realised that the first commit I made was on 30th April 2020. You may have noticed the 5 releases on Github and crates.io all happen to be on the 24th of the month. This will be the set date for releases but this time I opted to have it on the 30th to commemorate the project’s “birthday”. In this post I wanted to recollect my experience making my first project in Rust as well as share a sort of roadmap for the direction Paperoni will take for the coming year. Enjoy!
Looking back⌗
await a minute⌗
Working with async code in this project has been interesting. Making Paperoni had provided me with a great opportunity to really learn to use async code and I have been met with a few situations that were new to me. A key example was when I introduced the max_conn flag to set the maximum number of concurrent HTTP connections.
Previously, each async HTTP connection was run in its own Task which was fine until you have about 50 connections to make concurrently, which is more common than you’d think, and suddenly you’ve maxed out your network resource causing some requests to fail when they shouldn’t. The solution for efficiently making bulk HTTP calls asynchronously would be to use a Stream that then buffers n connections at a time and by passing the value of n to max_conn, a user can have more control over how many connections can run at a time. This blog post was of great help to understanding this.
Using EPUB as an output format⌗
As explained in a previous post, I opted to use the EPUB format for the downloaded articles due to the ease of converting the original HTML to XHTML. This was not entirely true. Despite the “X” in XHTML standing for eXtensible, it is stricter than HTML. Due to XHTML being fairly unpopular compared to both HTML and XML, there weren’t any existing crates that would create or even validate XHTML files. Even the crate I use to generate EPUBs doesn’t handle validation. This meant I had to create my own serializer to convert the HTML article into XHTML. While it sounds complex, I have managed to get away with it by adhering to the simpler rules of XHTML such as:
- All tags have both an opening and closing tag
- All attributes must be key-value pairs
- Ampersand and quoting characters must be escaped
However, the only means I have upto now for ensuring my documents are generated correctly is by opening them on readers like Foliate and Calibre’s ebook viewer. Calibre’s ebook viewer is the most lenient so if an EPUB doesn’t look okay on it, then I really messed up.
There are more takeaways that have been written in previous posts that you can read on such as making the Readability extractor. Let us now assess the current state of Paperoni.
Paperoni in the present⌗
The alpha tag⌗
LifePaperoni is good, but it can be (in) beta
~ Max Lord
At the time of this writing, the latest release is v0.4.0-alpha1. With a year of work behind this, one would wonder why it is still tagged as a project in alpha. In a lot of ways, the project is in pretty stable condition. However, there are things that aren’t provably stable. A key example is the module containing the readability algorithm, moz_readability. There is a considerable number of functions which lack unit tests and are difficult to test, ensuring they cover all the cases. This leads to a problem of “over-extracting” some articles, which leaves the navigation content, comments section or footer in an article. Fortunately, the original Mozilla version has a massive test suite which I do plan to port to Rust in this new annual cycle of Paperoni. Once the test suite has been ported over or at least a considerable amount of it, like 70%, then I’d be happy to change it to being in beta.
There are still some known issues affecting it in its current release. Let us find out what they are and why happen.
Progress bars⌗
With the v0.4.0-alpha1 release, I added progress bars provided by the indicatif crate which work pretty well. Unfortunately if paperoni is run on a terminal window narrower than the full length of the progress bar, it causes the bar to be redrawn on a new line as shown:
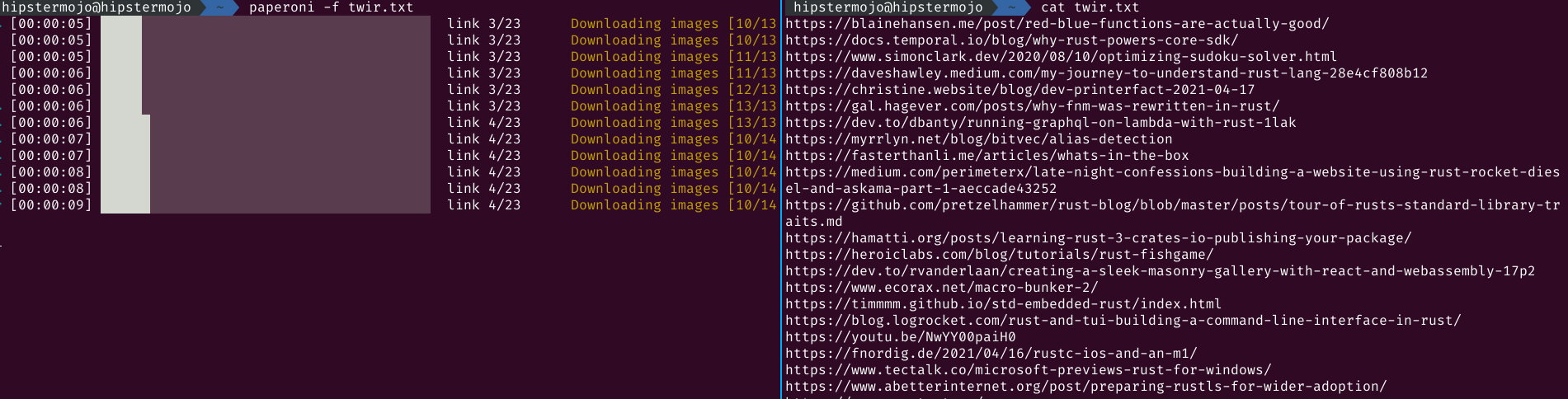
This happens to be a known issue of indicatif in #164 and #218 but since no comments have been made on either issue, it’s safe to assume that it won’t be fixed any time soon. I had sought for alternatives but because I wanted the progress bars to be colored on the terminal and support multiple platforms, I found no suitable alternatives.
Partial failures⌗
While adding error handling to Paperoni for v0.4.0-alpha1, I decided to let failed image downloads be a recoverable error meaning an article would still be generated, hence it only failed partially. If an article’s image could not be downloaded, the EPUB reader would have to then fetch the image from the original URL, a feature currently not supported on a reader like Foliate. But why would image downloads fail?
Some times the image downloads will fail because the URL is broken or the server hosting the image has an expired SSL certificate. But other times, I have found image downloads where the HTTP response was awkwardly constructed. In one scenario, my HTTP client surf, “confused” the MIME type of the image and believes an image is a JSON response 1. In another scenario, the server hosting the image returns an empty value for the Content-Type header. This used to happen when extracting articles from DigitalOcean but has been fixed. Both of these issues will be resolved by using the image crate which can then detect the image format by reading through the bytes sent in the response.
Now that we know what the current state of Paperoni is like, we can then turn our attention to its future for the next 12 months.
Looking forward⌗
As already mentioned, porting the test suite from Mozilla’s version is an important goal for the project for the next 12 months. There are other exciting plans as well which directly depend on each other. Some features will take much longer than others so it is not a guarantee that they will be available in consecutive releases. These features are:
- Extracting readability to its own library crate
- More supported platforms
- More performance enhancements
- Richer EPUB content
- Fine grained control of article extraction
- PDF exports
- Paperoni on web
Extracting readability to its own library crate⌗
Once the readability module has reached a satisfactory level of test coverage, I would like to make it an independent library crate. I had been asked once if I would make Paperoni itself a library crate but it has a lot of opinionated choices, including the async runtime it uses, which would not make a very flexible library. Nonetheless, if anyone does have a good reason to want to use Paperoni as a library in their own projects, do not hesitate to open an issue on GitHub so we can discuss.
More supported platforms⌗
At the moment, Paperoni still only has official releases for Ubuntu and Arch on the GitHub page, so users on other OSs can only either build from source or install from crates.io. This is obviously less than ideal and I will be looking to add GitHub actions for building on multiple platforms in coming releases.
More performance enhancements⌗
A key trait (no pun intended) associated with Rust programs is their speed. While I believe that Paperoni is quite fast at what it does, there is still room for improvement. This is mostly regarding the I/O operations like downloading images. Of course, before improving on performance, setting up proper benchmarks is crucial so that we can see if any of the work that goes into it will be of any significant benefit.
Richer EPUB content⌗
The current outputs generated by Paperoni look good for a large number of web sites you may try it with. However, some articles are actually harder to read in downloaded form due to lack of styling. This can be seen in articles with very wide images or code blocks (in the case of technical articles) that exceed the width of the screen. Improving on this should be a straightforward task for EPUB outputs as the styling is done in CSS. However, I couldn’t find an exact list of supported style declarations for the EPUB spec so I might have to approach it on a trial and error basis.
A crucial part of the improvements on styling would be to get syntax highlighting on code blocks working. A trivial approach would be to try and make it work with existing crates similar to Pygments like syntect. However the gold standard would be to have it also allow you to directly use libraries such as Pygments and Prism.js, rather than their substitutes, so that you can have code formatting the way you’d like.
I would also like to add an option for setting a cover of the EPUB output file. Initially, I wanted it to default to the first image in an article if any were available. However, most articles tend to have their images set in landscape mode so it would make the cover image look a little awkward.
Fine grained control of article extraction⌗
Some of the sites that the current extractor cannot extract articles from are generally not supported such as Twitter and Reddit threads. However, some times the thresholds set by Readability might be too strict for any content to be extracted from a site and so, having more power to configure the extraction process can help allow more websites to be extracted. Rather than have a user set about 50 different flags each time they want to use Paperoni to configure it, it would be better to have a dedicated configuration file with a set of defaults and presets that cover most scenarios. Nonetheless, setting configuration by passing flags will still be available.
PDF exports⌗
While Paperoni lacks support for exporting PDFs, I have thought about adding it but haven’t had the time to properly evaluate what that would look like. This is because I would like to handle PDF creation from HTML within Paperoni rather than delegate it to a third party library. A noteworthy suggestion on this particular issue was to try and convert the exported EPUBs to PDF. This would have worked very well but didn’t because:
The current lack of styling on EPUB exports caused the generated PDFs to have some of the text getting cut off the page.
I couldn’t find a native Rust library to handle the conversion which places the burden on the user to install it if they would want to get PDF exports working. The libraries outside of Rust that I evaluated for conversion were Pandoc and muPDF. EPUB conversion using Pandoc was very hit or miss and because Pandoc first needs to convert the EPUB into LaTeX, not all LaTeX engines would work for the conversion. muPDF was more resilient as it allows you to load most ebook formats that can then be saved as a PDF but it then had the issue of cutting the text off the screen. Fortunately, there are muPDF bindings for Rust so I can come back to this option in the future but as it stands, I am leaning more onto the option of generating the PDFs from within Paperoni.
This milestone is dependent on first adding better styling of the EPUB content and will also require the PDF exports to be consistent with the EPUB exports.
Paperoni on web⌗
Paperoni is only available as a CLI application at the moment, which is great but can be a turnoff for potential non-technical and even some technical users alike. Since its job is to download web articles, I think it would be great to have it as a web application as well. Web applications are easier to share with other people so it can help get a lot more people using it. Being a web application also unlocks a lot more features that can be built on Paperoni which are deserving of their own post.
Unfortunately, this isn’t a straightforward task to undertake. As a web application I’d want the backend to be in Rust as well but because I use the async-std runtime, I’m limited to only tide as an option for a backend framework that also uses the async-std runtime. There’s nothing wrong with tide, but I’d prefer to have options and the tokio runtime does have more for backend frameworks. It goes without saying, that running two separate async runtimes is not an option. In conclusion, this means I might either stick with async-std or have to move to tokio by the time work begins on this.
These are exciting times for working on and using Paperoni. If you have some of your own thoughts on cool features you'd like to see in Paperoni, feel free to open an issue on the GitHub repo so we can discuss. If you find any websites that don't work on Paperoni, also feel free to open an issue on the GitHub repo. I hope to see you in the next article.