Creating Paperoni - Part 2 of X: Improving the extractor
Article extraction described in the previous article was horribly unreliable. If you can remember,
it only involved finding the <article> element and taking this to be
representative of the article content. This is unreliable because
<article> elements are not exclusively used for article content only.
Instead, they are semantically used to represent independent content on a page.
Just look at the example on the MDN docs.
Even if they were to semantically represent article content only, you would be mistaken to think that
most websites would make web articles with semantic HTML anyway.
I began looking at algorithms proposed in academic papers such as the Boilerpipe algorithm,
a proposed improvement to Boilerpipe
and qRead. Unfortunately, none of these approaches
seemed to work for me as they either lacked online demos to try out or failed to extract even my blog post.
Some very smart people then pointed me to readability by Mozilla.
Readability is used by Firefox to extract the article content of a web page which is used by its reader view.
To open reader view on Firefox you can press the
![]() icon beside the address bar.
icon beside the address bar.
In the context of Rust, there is an existing crate for readability and a fork of it. Both crates are maintained by the same person and are based on the original Arc90 implementation.
The original readability algorithm was implemented by Arc90 which the Mozilla version is based on.
Naturally, I would use this crate to improve the extractor. However, the online demo of the readability crate would omit images from the extracted article which is something I would want an extractor to preserve.
Rather than using this crate and take a look at working around these issues, like a normal person would, I instead chose to make things interesting and try to port the Mozilla Readability algorithm to Rust. The rest of the blog will focus on explaining how I ported it.
Understanding Readability⌗

This will not cover everything on the Readability algorithm as that deserves a whole blog post on its own. The explanation given here is with reference to the Readability repository from April 13th 2020 (commit #52ab9b). The algorithm will have changed by the time you read this.
The short version⌗
A summarized explanation of Readability would be that it works by:
Removing DOM nodes that should not exist in the final article. Such nodes include
<script>,<style>and<br>elements.Scoring and removing more elements. Readability looks at element nodes and assigns a score based on things such as its tag name and CSS classes. The higher the score, the more likely an element is to be part of an article. Some of the elements removed here are those with classes or ids suggesting they are not part of the article e.g “comment” or “footer”.
Ranking the elements with the highest score. Readability picks the top 5 elements with the highest scores.
Creating an article node. All the content of the top ranked candidate element is added into a new
<div>and setting this as the article node.Post processing the article. This includes fixing URIs of images and links in the article to use absolute referencing.
Returning an article node.
With this in mind, we can now look at the Mozilla Readability codebase and see what considerations were made when choosing what can make up an article.
The longer version⌗
Getting familiar with the JS source code was not hard largely thanks to the fact that the code is well commented. The main function is the parse function:
const article = new Readability(document).parse();
The Readability class takes an HTMLDocument object and parse will then read through the HTMLDocument and return a possible article DOM node. In case the parse method is unable to return a DOM node of the article, it returns null.
The parse method is made up of 6 other functions:
unwrapNoscriptImagesremoveScriptsprepDocumentgetArticleMetadatagrabArticlepostProcessContent
These 6 functions are called by parse in the order listed here and by implementing them you would have walked through almost the entire Readability codebase. The least interesting of the 6 here is removeScripts, which just removes <script> and <noscript> elements from the HTMLDocument. Let us look at what the other 5 functions have in store for us.
unwrapNoscriptImages⌗
unwrap? I thought this was JavaScript…
This function checks for all <noscript> elements that are located after <img> elements and also contain only an <img> element within them. If they contain only an <img> element, then the <img> which is the previous sibling of the <noscript> is replaced by the <img> child of <noscript>.
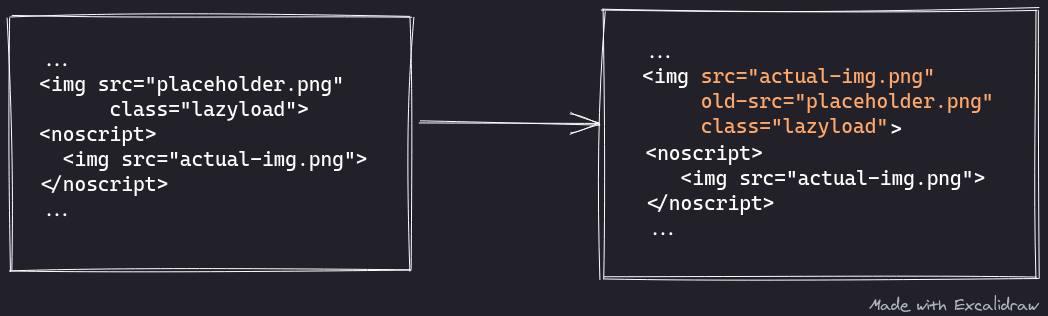
But what are <noscript> elements?
<noscript> elements are used to display alternate content on a browser only if JavaScript is disabled. Quite often, websites use this as a way to inform users that their websites cannot work properly without JavaScript enabled.
So why are we “unwrapping” these images?
Some websites use JavaScript to lazy load images, thus, saving bandwidth and speeding up load times. With lazy loading, images are only loaded if they are visible on screen. However if JavaScript is disabled, then the images can’t be seen as they need JavaScript to be loaded. Therefore, <noscript> elements can be used to contain images that are “eagerly” loaded.
Readability wants to ensure that the entire article can be read without needing any JavaScript thus it will prefer to use the images that are eagerly loaded. So it will replace any lazy loaded images with an eager loaded one if it is in the next <noscript> sibling.
Why not just use the images inside the <noscript> and skip unwrapping?
<noscript> elements are deleted by removeScripts which would get rid of images we would have wanted.
prepDocument⌗
This function prepares the HTMLDocument for extraction by removing styling elements and bad markup. The styling elements here are <style> elements. <font> elements (from HTML4 and no longer supported) are also replaced with <span> elements.
prepDocument also calls replaceBrs which takes care of cleaning up bad markup. Bad markup in this case, would be HTML that looks like part A below.
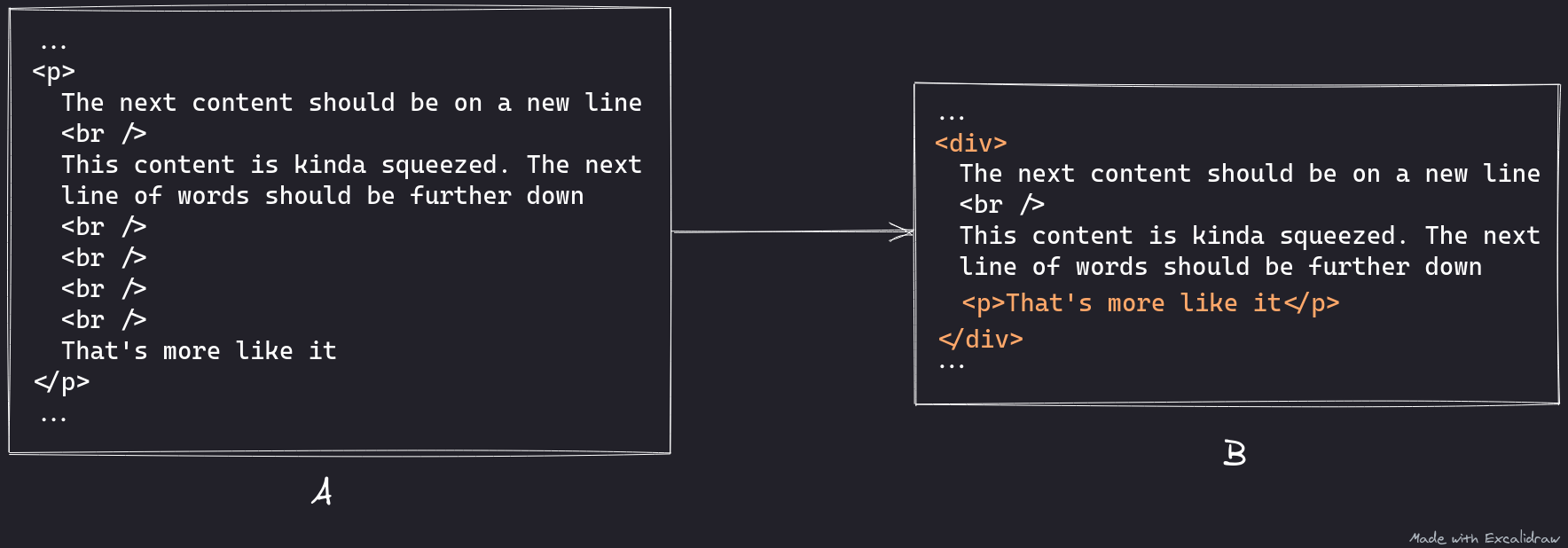
It is using an unbridled amount of <br> to add more space between content. replaceBrs looks to fix this by removing chains of <br> elements (2 or more) and collecting any non-whitespace content after it into a <p> element.
Note that the parent element in B is a <div>. When replaceBrs collected “That’s more like it” into a <p> element, it has to then change the parent into a <div> because you cannot have <p> elements in other <p> elements. If the parent in A was not a <p> element, then it will not be replaced.
getArticleMetadata⌗
This function extracts metadata from the article. The metadata includes:
- title
- byline. Byline refers to the author(s) of an article.
- excerpt. This is a short description of the article.
- sitename
All this information is searched for in the name attributes of <meta> elements of the HTMLDocument associated with each of the metadata. The table below summarises them.
| Metadata | Value in name attribute |
|---|---|
| title | dc:title, dcterm:title, og:title, weibo:article:title, weibo:webpage:title, title, twitter:title |
| byline | dc:creator, dcterm:creator, author |
| excerpt | dc:description, dcterm:description, og:description, weibo:article:description, weibo:webpage:description, description, twitter:description |
| sitename | og:site_name |
<meta> elements with these attributes may or may not exist, therefore, they can be null. However, the title and excerpt MUST exist. There is a fallback getArticleTitle function that looks for the article title from either the <title> element or <h1>/<h2> if only one exists in the document. If there is still no title, then it is set to an empty string. If no excerpt exists in the <meta> elements it is set to the first <p> element.
After the metadata has been retrieved, the content is then “unescaped”. This is where the escaped HTML entities are converted to the human readable form e.g " is replaced with ". Characters that were escaped as hexadecimal or decimal codes are also converted to their human readable form, e.g ß is replaced with ß.
grabArticle⌗
This function deals with scoring elements, removing elements and eventually returning a possible article node. It is the crux of the Mozilla Readability algorithm and is the largest function in the codebase with about 17 other functions called within it. Instead of going over all 17 functions I will give a general overview of how it works and explain the scoring system.
General Overview⌗
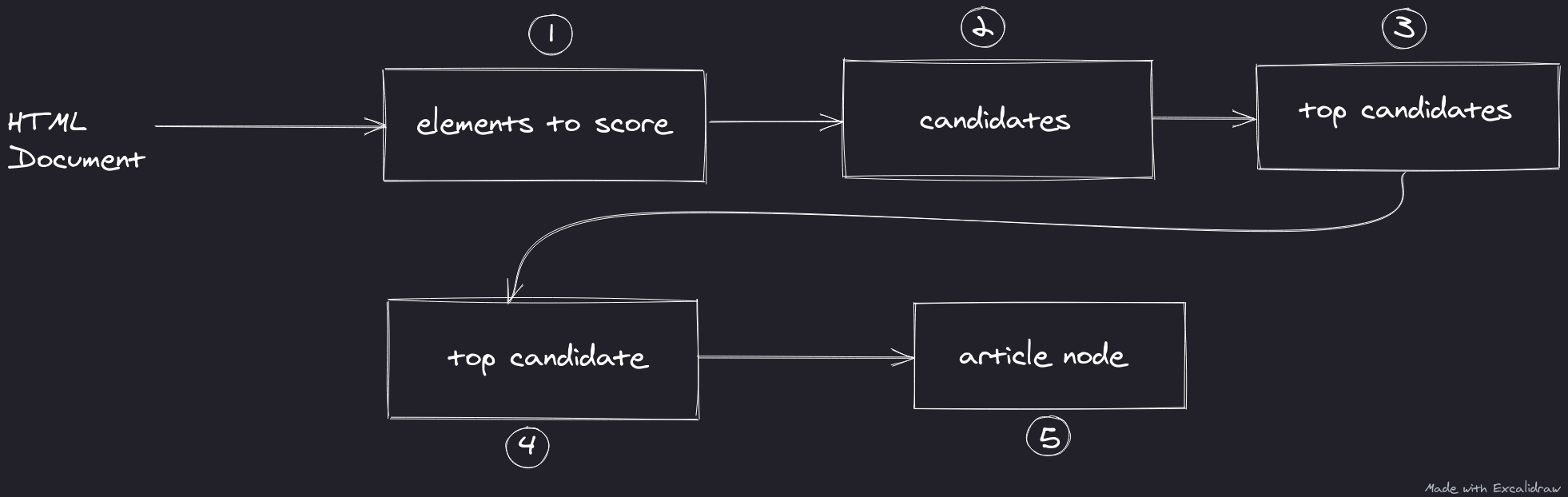
Borrowing from functional programming concepts, grabArticle can be thought of as a sequence of map and filter functions starting from nodes in an HTML document until a top candidate for the article node is found and then reducing it to an article node. Let us see how this is done.
- The function will begin traversing the DOM tree from the
<body>element in preorder traversal. Within each DOM node, the function can pick element nodes that will be scored or remove nodes such as those not visible to a user or have no content in them when they should. The element nodes to be scored are stored in an array that is used in step 2. - Each of the elements is given a score based on its attributes. The ancestors of each scored element are also given a portion of the score. Each scored ancestor is then added to an array of candidates, where each candidate can potentially be the root of the article.
- The candidates are ranked based on their score and the top candidates are picked. The default is to pick the top 5 candidates.
- If a top candidate somehow could not be found, the
<body>element is used as the top candidate. Otherwise, it checks if the other 4 top candidates may be a suitable replacement as top candidate. - A new
<div>is created that will contain all the children of the top candidate. This<div>is what will be the article node and is returned from the function.
In case the article node created has less content than is actually written in an article, this function runs again with different parameters set for what nodes to preserve. This can run upto 5 times, each time allowing more element nodes to be preserved.
During each failed attempt to grab an article node, the article node is added to an array of article nodes. Upon the 5th trial, grabArticle will pick the article node with the most content to be the article node. Even then, it is still likely that an article node cannot be grabbed and the function will then return null.
Let us now look at how nodes are scored to determine where the article could be.
Four score and seven years ago…⌗
Scoring of elements begins when initializeNode is called on an element node. The only nodes scored are content nodes, therefore, nodes containing media like <img>, <video> and <picture> are not considered here. Depending on an element’s tag name, it can affect its score positively or negatively. Below is a summary of the scores given to an element node based on its name.
| Tag name | Score |
|---|---|
| div | +5 |
| pre, td, blockquote | +3 |
| address, ol, ul, dl, dd, dt, li, form | -3 |
| h1, h2, h3, h4, h5, h6, th | -5 |
| everything else | 0 |
The classes and id set on an element are added to the score. The values in the class and id can either affect the score negatively (-25 points) or positively (+25 points). Negative values include “footer”, “meta” and “contact”. Positive values include “article”, “content” and “post”. The following would get a score of -22:
<pre class="contact">Find me on planet earth!</pre>
Element nodes then also get additional points for every comma in their text and upto 3 points for every 100 characters. When selecting top candidates, the candidates have their score adjusted by subtracting its link density from the score.
Link density refers to the amount of text inside links divided by the total amount of text in a node, so having a high link density will have a negative impact on the score.
Now that an article node has been extracted, it can undergo post processing.
postProcessContent⌗
Here the relative links are converted into absolute links. This applies to links in <a> tags as well as the sources for media elements like <img> and <video>. HTML classes of elements are also removed but can be configured to be preserved.
The Rusty bits⌗
Hopefully the previous section has given you a general understanding of Readability. Let us see how some of these concepts were translated into Rust code. As always, porting code to another language is not always a 1:1 situation and we’ll see how and why I took certain approaches.
Right tool for the right job⌗
Before porting the code, it is important to have the right tools for the job. In this case, having a good tool for manipulating the DOM is essential. Readability running in the browser already has the DOM API and when running in Node, it uses JSDOM. Since the Paperoni codebase already used kuchiki before, it seemed like a natural fit. The only viable alternative at the time was scraper which has a lot of great features but does not manipulate the DOM.
If you are looking to make a port of readability yourself, here are some of the things to consider.
Creating nodes⌗
Normally when accessing the element children of a DOM node, you would use a query selector. This is not the case with <noscript> elements. In fact you cannot access the children of a <noscript> using a query selector. Instead, you need to get the inner HTML text of a <noscript> and parse that as a DOM node. Creating a new Element node in Kuchiki from an HTML string was not possible until version 0.8.1 that added parse_fragment and came out in the middle of my porting of readability.
Traversing nodes⌗
A common mistake I made when working on functions such as replaceBrs was node traversal. When I find the first <br> element and was looking to access the next <br> element, I would use the next_sibling method. This is an issue because the next sibling node can be any of the accepted DOM node types. Consider the following HTML:
...
<div>
<p>Lorem ipsum</p>
<br />
<p>Ipsum lorem</p>
</div>
...
If you are currently on the <br /> element, the next sibling is not the <p> element. Instead, it will be the whitespace between the <br /> and the <p>.
Deleting nodes⌗
Deleting nodes in Kuchiki is not obvious in how it works. When deleting nodes in Kuchiki, you use the detach method. Let’s say we want to get rid of one <p> element with the id of “delete”, the code looks like this:
// -- snip --
let document = kuchiki::parse_html().one(html_str); // Create a document node from HTML.
let p_node = document.select_first("p#delete").expect("This element does not exist"); // Get the target node.
p_node.as_node().detach(); // Delete the node
// Now we confirm the node no longer exists.
assert_eq!(0, document.select("p#delete").expect("The query selector is invalid").count());
In Kuchiki, if you know your query selector is supposed to return just one node, you use
select_first, otherwise you useselectwhich means you expect 0 or more nodes.
The code above seems simple enough, as long as you don’t make the mistake of using p_node right after detach is called. This is because the node is now detached from the original document so methods like previous_sibling and next_sibling will return None.
Now let us try delete all the <p> elements in our document.
// -- snip --
let document = kuchiki::parse_html().one(html_str); // Create a document node from HTML.
let p_nodes = document.select("p").expect("The query selector is invalid"); // Get the p nodes.
for p_node in p_nodes {
p_node.as_node().detach(); // Delete the node
}
// Now we confirm the node no longer exists.
assert_eq!(0, document.select("p").expect("The query selector is invalid").count());
If the HTML passed into the code above was:
<!DOCTYPE html>
<html>
<body>
<p>One Mississippi</p>
<p>Two Mississippi</p>
<p>Three Mississippi</p>
</body>
</html>
then the code will fail. It will only ever delete the first <p> element.
But why?
The for loop above is desugared by Rust to the following code:
let mut p_nodes = document.select("p").expect("The query selector is invalid"); // Get the p nodes.
while let Some(p_node) = p_nodes.next() {
p_node.as_node().detach(); // Delete the node
}
When iteration 0 runs, detach is called and when the while block is about to start over, it calls next. Unfortunately, since the previous node is already gone, this seems to return None hence only running once, ever. A simple fix to this is to ensure you already know the next node to delete, so the code looks like this:
let mut p_nodes = document.select("p").expect("The query selector is invalid"); // Get the p nodes.
let mut next_node = p_nodes.next();
while let Some(p_node) = next_node {
next_node = p_nodes.next();
p_node.as_node().detach(); // Delete the node
}
Scoring nodes⌗
You may or may not have been asking yourself an important question about readability: Who is keeping score? We have seen how readability scores elements but haven’t seen where these scores are kept. In the JavaScript version, the DOM nodes have a readability field added to them for keeping score. This isn’t allowed in Rust. So how else can I keep score?
Originally I wanted to use a HashMap where the key is an Element node and the value is its score, but it is more than likely that two similar Element nodes will exist and have no way of being distinguished like in the example above for deleting nodes. Instead, I decided to add the score as an attribute of the element nodes called readability-score. This works great as long as there is no existing attribute in the html. As a neat side effect, the serialized HTML can also preserve this attribute for debugging purposes. There’s just 1 problem with this approach.
Accessing node attributes⌗
Whenever the readability score is being read from an element, I have often found myself needing to add a lexical scope to appease the (justifiably) almighty borrow checker:
let mut node: NodeDataRef<_> = document.select_first("p").unwrap();
let score: f32 = {
let node_attrs = node.attributes().borrow();
node_attrs.get("readability-score").unwrap().parse::<f32>().unwrap()
};
node = node.next_sibling().unwrap();
This was because I needed the borrowed RefCell<T> to drop after it has finished its use. If all the variables were in the same scope, the compiler will not allow you to mutate node as it is still immutably borrowed by node_attrs.
Hexcape sequences⌗
Until working on readability, I only knew of one way to escape characters in HTML, which is using the named ones like >,< and & (<, > and &).
However, HTML supports writing the escape codes using their utf-8 code. This can be represented either in decimal or hexadecimal. Take for example A, this can also be written as A or A. The unescape_html_entities function looks to convert these into human readable form. Parsing the hexadecimal escape code A is easy in Rust since I only need to call String::from_utf16 or String::from_utf16_lossy which will then give me a UTF-8 string.
assert_eq!(String::from_utf16(&[0x0041]), Ok("A".to_string()));
assert_eq!(String::from_utf16_lossy(&[0x0041]), "A".to_string());
The decimal escape code A could be parsed using String::from_utf8 or String::from_utf8_lossy but this is a problem once you get something like Ʃ which is Ʃ, since String::from_utf8 and String::from_utf8_lossy expect Vec<u8> and 425 cannot fit in a single byte.
assert_eq!(String::from_utf8(&vec![65]), Ok("A".to_string()); // Works fine
assert_eq!(String::from_utf8(&vec![425]), Ok("Ʃ".to_string()); // Panics
So instead, I convert decimal escape codes to hexadecimal then parse from utf-16. Here is a list of the escape codes for reference.
Are we readability yet?⌗
The readability port is by no means production ready. It is serviceable, meaning it will probably work well enough as is. It has certainly made Paperoni much more useful on a lot of sites. I might consider extracting the readability port as its own crate but before then, I should at least prove it is compliant with the original implementation by adding the test suite which is quite large (1400+ tests).
Congratulations on reading this very long post to the end! You can try out Paperoni for yourself by downloading from crates.io or checking the releases page but that only has .deb and .aur binaries for now. It is still in alpha so expect a couple of things to not work well (but be addressed in the next blog post!). I hope to see you in the next one.